This post is consisted of mostly direct quotes from the article posted at the bottom of the page. I put them here to remember the key points I learned in the article. I am not claiming any authorship in any way of the content below
Create nonclustered indexes on the columns that are frequently used in predicates, GROUP BY and JOIN conditions in queries. However, you should avoid adding unnecessary columns. Adding too many index columns can adversely affect disk space and index maintenance performance.
Covering indexes can improve query performance because all the data needed to meet the requirements of the query exists within the index itself. That is, only the index pages, and not the data pages of the table or clustered index, are required to retrieve the requested data; therefore, reducing overall disk I/O. For example, a query of columns a and b on a table that has a composite index created on columns a, b, and c can retrieve the specified data from the index alone.
Write queries that insert or modify as many rows as possible in a single statement, instead of using multiple queries to update the same rows. By using only one statement, optimized index maintenance could be exploited.
Evaluate the query type and how columns are used in the query. For example, a column used in an exact-match query type would be a good candidate for a non-clustered or clustered index.
Index Design Basics
The selection of the right indexes for a database and its workload is a complex balancing act between query speed and update cost. Narrow indexes, or indexes with few columns in the index key, require less disk space and maintenance overhead. Wide indexes, on the other hand, cover more queries. You may have to experiment with several different designs before finding the most efficient index. Indexes can be added, modified, and dropped without affecting the database schema or application design. Therefore, you should not hesitate to experiment with different indexes.
General Index Guidelines
Large numbers of indexes on a table affect the performance of INSERT, UPDATE, DELETE, and MERGE statements because all indexes must be adjusted appropriately as data in the table changes. For example, if a column is used in several indexes and you execute an UPDATE statement that modifies that column’s data, each index that contains that column must be updated as well as the column in the underlying base table (heap or clustered index).
Create nonclustered indexes on the columns that are frequently used in predicates and join conditions in queries. However, you should avoid adding unnecessary columns. Adding too many index columns can adversely affect disk space and index maintenance performance.
Covering indexes can improve query performance because all the data needed to meet the requirements of the query exists within the index itself. That is, only the index pages, and not the data pages of the table or clustered index, are required to retrieve the requested data; therefore, reducing overall disk I/O. For example, a query of columns a and b on a table that has a composite index created on columns a, b, and c can retrieve the specified data from the index alone.
Consider the order of the columns if the index will contain multiple columns. The column that is used in the WHERE clause in an equal to (=), greater than (>), less than (<), or BETWEEN search condition, or participates in a join, should be placed first. Additional columns should be ordered based on their level of distinctness, that is, from the most distinct to the least distinct.
The uniqueness of values in a column affects index performance. In general, the more duplicate values you have in a column, the more poorly the index performs. On the other hand, the more unique each value, the better the performance. When possible, implement unique indexes.
For composite indexes, take into consideration the order of the columns in the index definition. Columns that will be used in comparison expressions in the WHERE clause (such as WHERE FirstName = ‘Charlie’) should be listed first. Subsequent columns should be listed based on the uniqueness of their values, with the most unique listed first.
Create nonclustered indexes on columns used frequently in your statement’s predicates and join conditions.
Index Structure
Clustered Index Structure
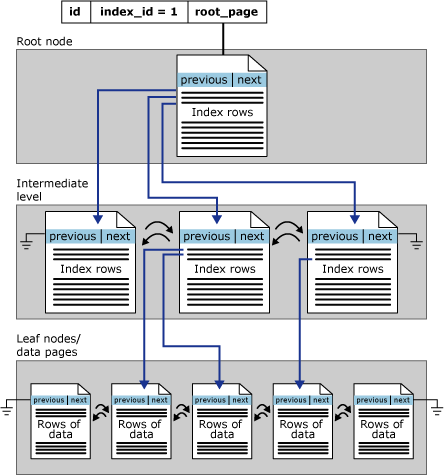
Non-clustered Index Structure
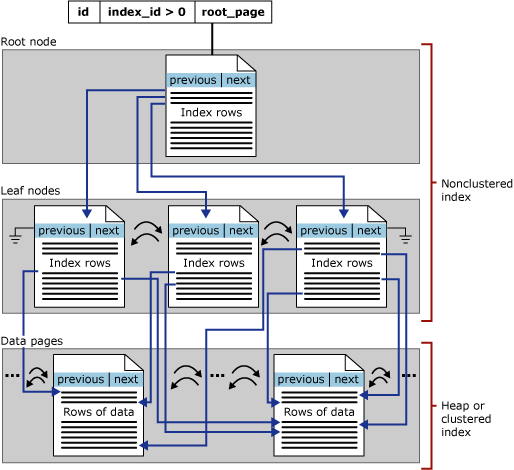
Non-Clustered Indexes in SQL Server
14 SQL Server Indexing Questions You Were Too Shy To Ask
Views – 3470